1. barchart
x축 변수 1개로만 그리는 경우
xxxxxxxxxxggplot(Group_Data) +geom_bar(aes(x = as.factor(Counts),fill = ..count..)) +xlab("") + ylab("") +scale_fill_gradient(low = "#CCE5FF", high = "#FF00FF") +theme_classic() + ggtitle("Continuous Color")ggplot(Group_Data) +geom_bar(aes(x = as.factor(Counts),fill = Day),alpha = 0.4) +xlab("") + ylab("") +theme_classic() + ggtitle("Discrete Color")ggplot(Group_Data) +geom_bar(aes(x = as.factor(Counts),fill = Day),alpha = 0.4,position = "dodge") +xlab("") + ylab("") +theme_classic() + ggtitle("Discrete Color\n position Dodge")
x축, y축 변수 2개로 그리는 경우, stat = 'identity' 사용합니다.
xxxxxxxxxxggplot(Group_Data) +geom_bar(aes(x = Year, y = Mean, fill = Day), stat = 'identity') +scale_fill_manual(values = c("#C2DAEF","#C2EFDD","#BBAAE9","#E9F298","#FABDB3")) +theme_classic()ggplot(Group_Data) +geom_bar(aes(x = Year, y = Mean, fill = Day), stat = 'identity') +scale_fill_manual(values = c("#C2DAEF","#C2EFDD","#BBAAE9","#E9F298","#FABDB3")) +theme_classic() +facet_wrap(~Day)


2. histogram
주로 binwidth옵션을 사용하여 그래프 조정합니다.
xxxxxxxxxxggplot(STOCK) +geom_histogram(aes(x = High , fill = ..x.. ),binwidth = 1000) +scale_fill_gradient(low = "#CCE5FF", high = "#FF00FF") +theme_classic() + labs(fill = "Labels Name")ggplot(STOCK) +geom_histogram(aes(x = High , fill = Day ),binwidth = 1000, alpha = 0.4) +theme_classic() + labs(fill = "Labels Name")ggplot(STOCK) +geom_histogram(aes(x = High , fill = Day ),binwidth = 1000, alpha = 0.4, position = "dodge") +theme_classic() + labs(fill = "Labels Name")

3. density plot
히스토그램과 비슷하게 작성합니다.
xxxxxxxxxxggplot(STOCK) +geom_density(aes(x = High)) +theme_classic() + labs(fill = "Labels Name")ggplot(STOCK) +geom_density(aes(x = High , fill = Day ), alpha = 0.4) +theme_classic() + labs(fill = "Labels Name") +facet_wrap(~ Day, ncol = 1)ggplot(STOCK) +geom_density(aes(x = High , fill = Day ),alpha = 0.4) +theme_classic() + labs(fill = "Labels Name") +facet_wrap(~Day, nrow = 1) +theme(axis.text.x = element_text(size = 9, angle = 45,hjust = 1))

4. boxplot & jitter plot
x축은 Descrete 변수를, y축에는 Continuous 변수를 배치해야합니다.
xxxxxxxxxxggplot(STOCK) +geom_boxplot(aes(x = Day, y = Volume, fill = Day),alpha = 0.4, outlier.color = 'red') +theme_bw()ggplot(STOCK) +geom_jitter(aes(x= Day, y= Volume,col = Day),alpha = 0.4) +theme_bw()ggplot(STOCK) +geom_boxplot(aes(x = Day, y = Volume, fill = Day),alpha = 0.4, outlier.color = 'red') +geom_jitter(aes(x= Day, y= Volume,col = Day),alpha = 0.4) +theme_bw()

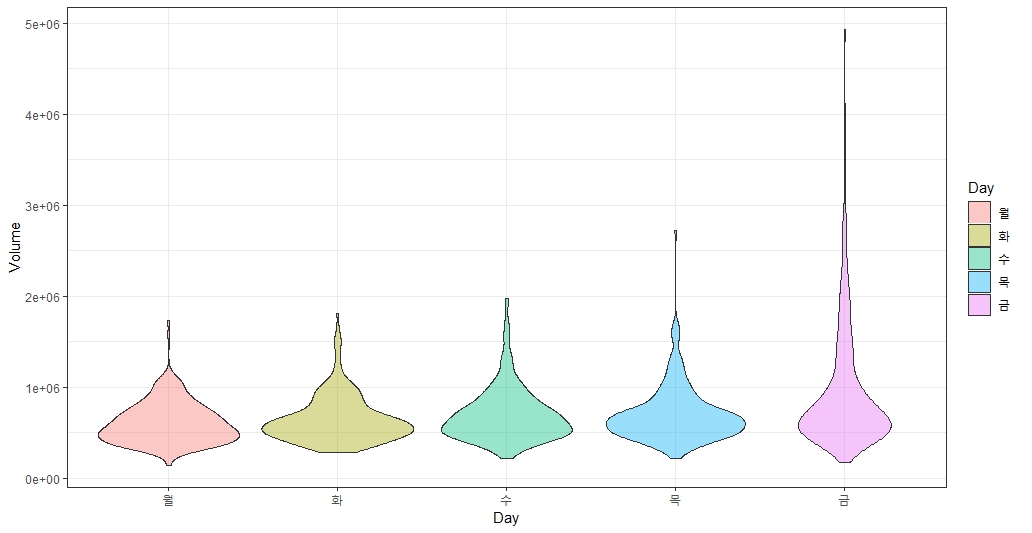
5. violin plot
박스플롯과 그리는 방법은 동일합니다.
xxxxxxxxxxggplot(STOCK) +geom_violin(aes(x = Day, y = Volume, fill = Day),alpha = 0.4) +theme_bw()
6. scatter plot
두 변수 모두 Continuous 변수를 넣되, size, shape 등을 자유롭게 바꿀 수 있습니다.
xxxxxxxxxxggplot(STOCK) +geom_point(aes(x = Open, y = Stock.Trading,col = High, size = log(Volume), shape = Year)) +scale_color_gradient(low = "#CCE5FF", high = "#FF00FF") +scale_shape_manual(values = c(19,20,21,22,23)) +labs(col = "Color", shape = "Shape", size = "Size") +theme_bw()
- point에 적용되는 shape는 종류가 여러가지가 있습니다. 인터넷에 shape별 고유번호가 나와 있으니, 참고하시면 좋을 것입니다. (링크 : http://sape.inf.usi.ch/quick-reference/ggplot2/shape)

7. smooth plot
geom_smooth()에서 주로 건드리는 옵션은 method, se옵션입니다.
xxxxxxxxxxggplot(STOCK) +geom_smooth(aes(x = Open, y = Stock.Trading),method = 'lm', size = 2,col = '#8A8585') +theme_bw()ggplot(STOCK) +geom_smooth(aes(x = Open, y = Stock.Trading),method = 'lm',se = FALSE, size = 2,col = '#8A8585') +theme_bw()ggplot(STOCK) +geom_smooth(aes(x = Open, y = Stock.Trading),method = 'loess', size = 2,col = '#8A8585') +theme_bw()ggplot(STOCK) +geom_smooth(aes(x = Open, y = Stock.Trading),method = 'loess',se = FALSE, size = 2,col = '#8A8585') +theme_bw()

8. abline, vline, hline
그래프에 보조선을 추가하고 싶을 때, geom_abline(), geom_vline(), geom_hline()을 이용하여 선을 그릴 수가 있습니다.
- geom_vline() : 수직선
- geom_hline() : 수평선
- geom_abline() : 절편, 기울기를 줘서 작성하는 직선
xxxxxxxxxxggplot(NULL) +geom_vline(xintercept = 10, linetype = 'dashed',col = 'royalblue', size = 3) +geom_hline(yintercept = 10, linetype = 'dashed',col = 'royalblue', size = 3) +geom_abline(intercept = 0, slope = 1, col = 'red',size = 3) +theme_bw()

9. step plot
geom_step()은 이후에 그릴 line 그래프와 매우 비슷한 그래프입니다. 특히 생존시간에 따른 Hazard Ratio를 표현하기 매우 좋습니다.
xxxxxxxxxxHazard_Ratio = c(0.1,0.3,0.4,0.45,0.49,0.52,0.6,0.65,0.75,0.8,0.95)Survival_Time = c(1,2,3,4,5,6,7,8,9,10,11)ggplot(NULL) +geom_step(aes(x = Survival_Time, y = Hazard_Ratio),col = 'red') +scale_x_continuous(breaks = Survival_Time) +theme_classic()

10. density_2d plot
2차원 평면 상에서 밀도 그래프를 표시하고자 하는 그래프입니다. geom_density2d()를 사용합니다.
xxxxxxxxxxggplot(STOCK) +geom_point(aes(x= log(Stock.Trading), y = Open, col = Open)) +geom_density2d(aes(x= log(Stock.Trading), y = Open)) +scale_color_gradient(low = "#E93061", high = "#574449") +theme_bw()

11. Text plot
Scatter Plot을 그리는 것과 같은 원리입니다. 하지만 geom_text()는 점 대신에 지정해준 텍스트를 그래프상에 표시합니다.
xxxxxxxxxxSL = sample(1:nrow(STOCK), 200, replace = FALSE)ggplot(STOCK[SL,]) +geom_text(aes(x = Date , y= Open, label = Open,col = Open), size = 2.5) +scale_color_gradient(low = "#E93061", high = "#574449") +theme_bw()

12. line plot & Time Series Plot
geom_line()은 먼저 데이터가 x축 변수와 y축 변수가 1 대 1 매칭이 되는지 확인을 하여야 합니다. 만약 그렇지 않은 경우, 그래프가 이상하게 나오는 것을 확인할 수가 있습니다.
line plot은 항상 group 옵션을 지정해 주어야 합니다. 기본적으로 선을 1개 그리려고 할 때는 group = 1을 설정하고, 색으로 구분해서 그릴 경우는 구분 변수를 설정해주면 됩니다.
xxxxxxxxxxggplot(STOCK) +geom_line(aes(x= Year, y = Open),group = 1) +theme_bw()
이런 경우는 x축과 y축 변수가 1 대 1 매칭이 되지 않았기에 생긴 문제입니다. 그렇기에 geom_line()그래프를 그릴 때는 종종 집계된 데이터를 활용하여 그리는 것이 맞습니다. 지금은 1대1 매칭이 되는 Date 변수를 x축으로 하여 그래프를 그리도록 하겠습니다.
xxxxxxxxxxggplot(STOCK) +geom_line(aes(x = Date, y = Open), group = 1) +theme_bw()ggplot(STOCK) +geom_line(aes(x = Date, y = Open,col = Year, group = Year)) +theme_bw()


13. Vertical Error bar plot
geom_errorbar()을 이용하여 그래프에 편차, 범위 등의 정보를 표현해줄 수 있습니다.
ymin. ymax을 통해 error bar plot의 범위를 정해줍니다.
xxxxxxxxxxSTOCK[1100:1226,] %>%mutate(Diff = Close - Open ,group = ifelse(Diff > 0 ,"Up","Down")) %>%ggplot() +geom_errorbar(aes(x = Date, ymin = Low, ymax = High,col = group),width = 4) +scale_color_manual(values = c("red","blue")) +theme_bw()

14. Horizontal Error bar
geom_errorbarh()을 이용하면 x축을 기준으로 하는 error bar plot을 그릴 수 있습니다.
xxxxxxxxxxggplot(Group_Data) +geom_errorbarh(aes(xmin = Mean, xmax = Max, y= Year,col = Year), height = 0.3)+theme_classic() +facet_wrap(~ Day, nrow = 1)

15. Corr plot
corrplot 패키지를 이용하면 상관계수를 이용하여 그래프를 그릴 수가 있습니다.
xxxxxxxxxxCor_matrix = cor(iris[,1:4]) # iris는 R 기본 내장 데이터library(corrplot)corrplot(Cor_matrix , method = "color", outline = T, addgrid.col = "darkgray",order="hclust", addrect = 4, rect.col = "black",rect.lwd = 5,cl.pos = "b", tl.col = "indianred4",tl.cex = 1, cl.cex = 1, addCoef.col = "white",number.digits = 2, number.cex = 1,col = colorRampPalette(c("darkred","white","midnightblue"))(100))

16. Heat map
히트맵은 두 Descrete 변수를 기준으로 집계된 데이터를 통해 만들 수 있습니다.
xxxxxxxxxxggplot(Group_Data) +geom_tile(aes(x = Year, y = Day, fill = Counts),alpha = 0.6) +scale_fill_gradient(low = "#C2DAEF", high = "#8A8585") +theme_classic()

17. Ribbon Plot
geom_ribbon()은 error bar plot의 라인 버전이라고 생각하시면 됩니다.
xxxxxxxxxxggplot(STOCK) +geom_ribbon(aes(x= Date, ymin = log(Low) - 0.5, ymax = log(High) + 0.5),fill = 'royalblue' , alpha = 0.2) +theme_classic()ggplot(STOCK) +geom_ribbon(aes(x= Date, ymin = log(Low) - 0.5, ymax = log(High) + 0.5),fill = 'royalblue' , alpha = 0.2) +geom_point(aes(x= Date, y = log(Low) - 0.5), col = '#8A8585', alpha = 0.8) +geom_point(aes(x= Date, y = log(High) + 0.5), col = '#8A8585', alpha = 0.8) +geom_line(aes(x = Date, y = log(Open)),group =1 , col = '#C2DAEF' , linetype = 'dashed', size = 0.1) +geom_point(aes(x = Date, y = log(Open)),col = 'red', alpha = 0.4) +theme_classic() +ylab("") + xlab("")

18. Ridge Plot
geom_density_ridges_gradient()을 활용하면 density plot을 여러 축에 나눠서 그릴 수가 있습니다.
xxxxxxxxxx# install.packages("ggridges")library(ggridges)ggplot(STOCK) +geom_density_ridges_gradient(aes(x = log(High) + 0.2 , y= Year, fill = ..x..),gradient_lwd = 1.) +theme_ridges(grid = FALSE) +scale_fill_gradient(low= "#8A8585", high= "#C2DAEF") +theme(legend.position='none') + xlab("") + ylab("")

19. Area Plot
geom_area()을 활용하여 누적 영역 그래프를 그릴 수가 있습니다.
xxxxxxxxxxggplot(Group_Data) +geom_area(aes(x= as.numeric(as.character(Year)), y = Mean , fill = Day ),alpha = 0.4) +theme_classic() +xlab("")

20. Polygon Plot
geom_polygon()이라는 명령어가 있지만, 해당 명령어는 쓰기가 조금 까다롭습니다. 요구하는 데이터 입력 방식이 간단하지가 않습니다. 그렇기 때문에 stat_ellipse()명령어를 사용하여 polygon 플랏을 그리도록 하겠습니다.
stat_ellipse()처럼 stat으로 시작하는 명령어는 옵션에 geom = 'polygon' 처럼 어떻게 그래프를 그릴 것인지 옵션을 주어야 합니다.
xxxxxxxxxxggplot(STOCK) +stat_ellipse(geom = 'polygon',aes(x = Volume, y = Stock.Trading, fill = Year), alpha = 0.2) +geom_point(aes(x = Volume, y = Stock.Trading, col = Year),alpha = 0.2) +theme_classic() +# 그래프 가시성을 위해 축 범위 조절xlim(0,1000000) + ylim(0,50000000000)

21. Rect Plot(Waterfall Chart)
geom_rect()를 이용하여 정사각형 그래프를 그릴 수가 있습니다. 이 그래프를 이용하여 널리 알려진 waterfall chart를 그릴 수가 있습니다.
xxxxxxxxxxggplot(Group_Data) +geom_rect(aes(xmin = as.numeric(as.character(Year)) - 0.5 ,xmax = as.numeric(as.character(Year)) + 0.5,ymin = Median, ymax = Max, fill = Year), alpha = 0.4) +geom_hline(yintercept = mean(Group_Data$Median),linetype = 'dashed', col = 'red') +theme_classic() +facet_wrap(~Day, nrow = 1)

댓글
댓글 쓰기