Ch4. Resampling 방법론
이전 챕터에서는 앙상블에 대해 다루었습니다. 앙상블을 요약하자면, Training Set을 Resampling할 때 마다, 가중치를 조정할 것인지 말 것인지를 다루는 내용이었습니다. 이번에는 구체적으로 Resampling 방법들에 대해 다루어 보고자 합니다.
1. Resampling의 목적과 접근 방식
모형의 변동성(Variability)을 계산하기 위해서 입니다.
Training Set으로 모형을 만들고, Test Set으로 Error rate를 계산하며, 이를 반복합니다.
각 실행 별, Error Rate 값이 계산이 될 것이며, 해당 Error rate의 분포를 보고 모형의 성능을 평가할 수 있습니다.
Model Selection : 모형의 성능을 Resampling 방법론을 통해 평가한다면, 모델링 과정에서 어떤 변수를 넣어야 하고, 혹은 모형의 유연성(Flexibility)을 어느정도로 조절하는 것이 적당한지 결정을 할 수 있기 때문에 매우 중요한 방법론 중 하나입니다.
- 모형의 유연성에 대해서는 다음 챕터에서 설명하도록 하겠습니다.
2. Leave-One-Out Cross Validation(LOOCV)
LOOCV는 n개의 데이터에서 1개를 Test Set으로 정하고 나머지 n-1개의 데이터로 모델링을 하는 방법을 의미합니다.
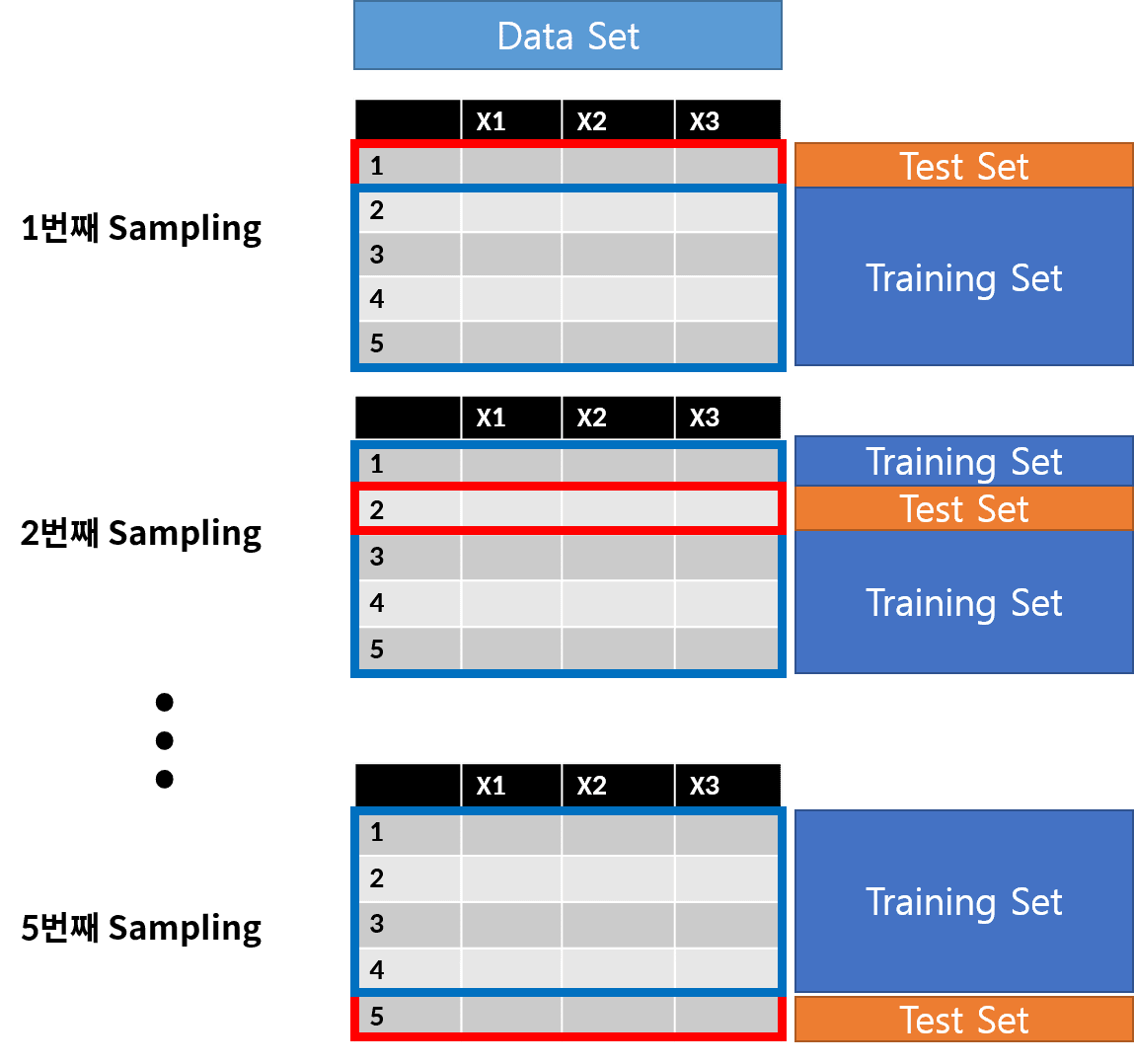
- LOOCV 방법은 데이터 수 n이 크다면, n번의 모델링을 진행해야되기 때문에, 시간이 오래 걸립니다.
- 회귀, 로지스틱, 분류모형 등에 다양하게 적용할 수 있습니다.
3. K - Fold Cross - Validation
연산시간이 오래걸린 다는 것은 곧, 작업시간이 길어진다는 의미이며 이는 곧 야근을 해야된다는 소리와 다를게 없어집니다. 그래서 시간이 오래걸리는 LOOCV를 대채하기 위하여 K-Fold Cross - Validation이 존재합니다.

위 그림은 데이터 셋을 총 4개의 Set로 구성하였습니다. Cross - Validation은 각 Set가 돌아가면서 Test Set의 역할을 하는 것입니다. 첫번째 Sampling에서는 Set 1이 Test Set이 되어주고 나머지 3개의 Set가 Train Set이 되어 예측 모형을 만듭니다. 데이터를 4분류 했기 때문에, K = 4 즉, 4-fold Cross Validation입니다.
여기까지가 기계학습에서 다루는 필수적인 Sampling 방법론들이었습니다. 여기까지 다룬 것은 극히 일부분이며 매우 쉽습니다. 다음 시간부터 학습 모델을 어떻게 만드는지에 대해 다루어보도록 하겠습니다.