Ch1. 기계학습에 대한 정의
데이터로부터 패턴을 뽑아내는 자동화 프로세스를 기계학습이라고 정의합니다. 기계학습의 적용 분야는 매우 다양한데, 예시를 들자면 다음과 같습니다.
- 스팸메일 분류 알고리즘
- 고객들의 구매 패턴 분석 알고리즘
- 환자 진단 알고리즘
- 비젼, 음성, 문자 등 많은 분야에 적용이 가능
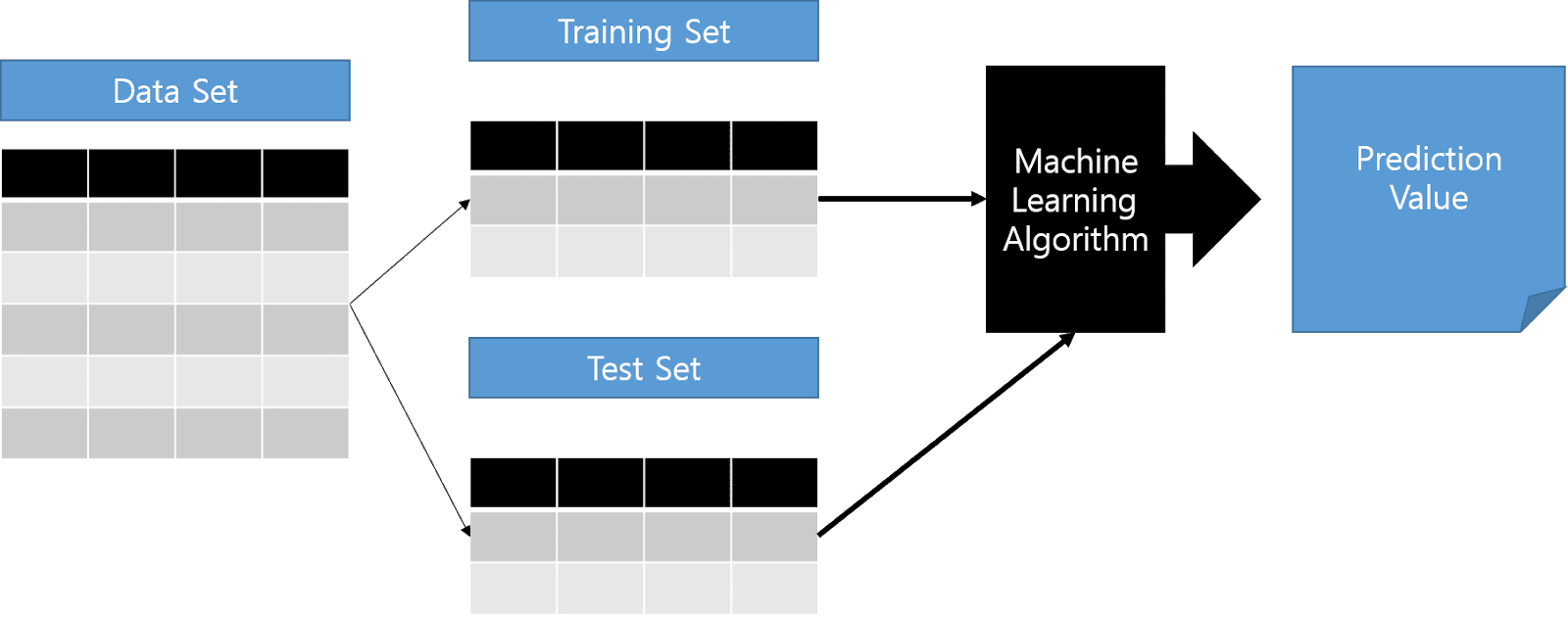
기계학습 모형의 가장 큰 목적은 예측 모형을 만드는 것에 있습니다. 좋은 예측 모형이란, 현재에 존재하지 않는 데이터에 대해서도 예측값을 잘 맞추는 모형을 좋은 모형이라고 하며, 이런 모형을 일반화(generalize)가 잘 되었다고 합니다.
Ch2. 기계학습에서 주의할 점
기계학습에서 예측 모형의 정확성을 떨어트리는 문제점은 2가지가 있습니다.
- Underfitting
Underfitting은 Feature 변수가 Response 변수를 너무 간단하게 설명하려고 할 때 발생합니다.
- Overfitting
Overfitting은 Underfitting과 대조적으로 알고리즘이 너무 복잡하고 데이터에 너무 밀접하게 짜여졌을 때, 잡음(noise)에 예민해지는 문제가 발생합니다.
Over(Under)fitting은 예시를 들자면, 이런 경우가 있습니다. 대부분의 대학교 학과에서 최소 강의 1개 이상은 시험 족보가 돌아다니길 마련입니다. 하지만 현명하신 교수님들께서는 족보그대로 시험문제를 출제하는게 아니라, 족보에서 60%, 안나왔던 문제 40%를 배치시켜 균형있게 문제를 내십니다.
이런 경우,
- Underfitting은 그냥 공부를 안해서 시험을 못보는 거라고 할 수 있습니다.
- Overfitting은 공부는 열심히 했는데 족보만 공부해가지고 새로운 문제를 못풀어 시험을 못보는 거라고 할 수 있습니다.
Machine Learning은 '학습'입니다. 기계한테 데이터를 학습시킴으로써 새로운 데이터가 들어왔을 때, 문제 없이 예측값을 뽑아낼 수 있느냐가 중요합니다. 그런 이유로 항상 예측모형을 학습시킬 때, Training Set과 Test Set을 분리시켜 모형의 신뢰도를 높이고자 하는 앙상블 기법을 주로 사용합니다.